LANZAN UN MODELO DE VÍDEO INTERACTIVO QUE SIMULA MUNDOS GENERATIVOShttps://x.com/odysseyml https://experience.odyssey.world/Odyssey es un laboratorio de IA cuya misión es empoderar a los creativos para contar historias inéditas. Comenzamos este viaje desarrollando modelos de mundo para acelerar la producción de películas y videojuegos, pero gracias a nuestra investigación, ahora estamos viendo los primeros atisbos de un medio de entretenimiento completamente nuevo.
A esto lo llamamos video interactivo: video que puedes ver e interactuar con él, imaginado íntegramente por IA en tiempo real. Es algo similar al video que ves a diario, pero con el que puedes interactuar y conectar de forma atractiva (con el teclado, el teléfono, el control y, eventualmente, el audio). Considéralo una versión preliminar del Holodeck.
Un avance de investigación del vídeo interactivoHoy marca el inicio de nuestro viaje para hacer realidad esto, con el lanzamiento público de nuestra primera experiencia de video interactiva. Esto se basa en un nuevo modelo de mundo que demuestra capacidades como la generación de píxeles realistas, el mantenimiento de la consistencia espacial, el aprendizaje de acciones a partir del video y la generación de secuencias de video coherentes de 5 minutos o más. Lo más destacable es su capacidad para generar y transmitir nuevos fotogramas de video realistas cada 40 ms.
La experiencia actual se siente como explorar un sueño lleno de fallos: cruda, inestable, pero innegablemente nueva. Aunque su utilidad es limitada por ahora, las mejoras no se basarán en motores de juego creados a mano, sino en modelos y datos. Creemos que este cambio rápidamente desbloqueará visuales realistas, una interactividad más profunda, una física más rica y experiencias completamente nuevas que simplemente no son posibles en el cine y los videojuegos tradicionales.
En un horizonte temporal lo suficientemente largo, esto se convierte en el simulador del mundo, donde los píxeles y las acciones se ven y se sienten indistinguibles de la realidad, lo que permite miles de experiencias nunca antes posibles.
Impulsado por un modelo mundial en tiempo realUn modelo de mundo es, en esencia, un modelo dinámico condicionado por la acción. Dado el estado actual del mundo, una acción entrante y un historial de estados y acciones, el modelo intenta predecir el siguiente estado del mundo en forma de fotograma de vídeo. Es esta arquitectura la que está impulsando el vídeo interactivo, junto con otras aplicaciones de gran alcance.
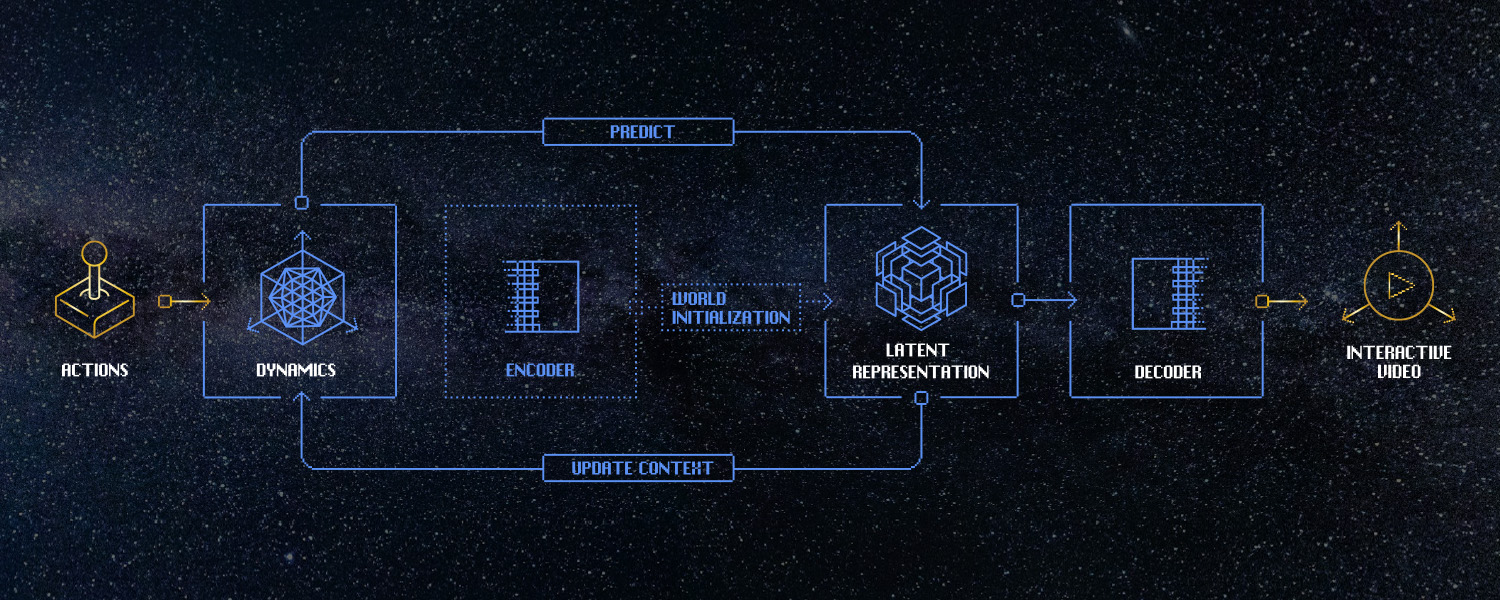
En comparación con los modelos de lenguaje, imagen o vídeo, los modelos de mundo aún están en sus primeras etapas, especialmente aquellos que se ejecutan en tiempo real. Uno de los mayores desafíos es que requieren modelado autorregresivo, que predice el estado futuro a partir del estado previo. Esto significa que los resultados generados se retroalimentan al contexto del modelo. En el lenguaje, esto es menos problemático debido a su espacio de estados más acotado. Sin embargo, en los modelos de mundo —con un estado de dimensiones mucho mayores— puede generar inestabilidad, ya que el modelo se desvía del soporte de su distribución de entrenamiento. Esto es particularmente cierto en los modelos en tiempo real, que tienen menor capacidad para modelar dinámicas latentes complejas. Mejorar esto es un área de investigación en la que estamos profundamente comprometidos.
Para mejorar la estabilidad autorregresiva de este avance de investigación, lo que compartimos hoy puede considerarse un modelo de distribución estrecha: se preentrena con video del mundo y se posentrena con video de un conjunto más pequeño de lugares con cobertura densa. La desventaja de este posentrenamiento es que perdemos cierta generalidad, pero ganamos una generación autorregresiva más estable y de larga duración.
Para ampliar la generalización, ya estamos avanzando rápidamente en nuestro modelo de mundo de próxima generación. Este modelo, que se muestra en los resultados brutos a continuación, ya muestra una gama más rica de píxeles, dinámicas y acciones, con una generalización notablemente más sólida.
De cara al futuro, investigamos representaciones del mundo más ricas que capturen la dinámica con mucha mayor fidelidad, a la vez que aumentan la estabilidad temporal y la persistencia del estado. Paralelamente, ampliamos el espacio de acción, del movimiento a la interacción con el mundo, aprendiendo acciones abiertas a partir de vídeos a gran escala.
Aprendiendo no sólo el video, sino las acciones que lo moldeanLas primeras investigaciones sobre vídeo interactivo se han centrado en el aprendizaje de píxeles y acciones de mundos de juegos como Minecraft o Quake , donde los píxeles están restringidos, el movimiento es básico, las acciones posibles son limitadas y la física es simplificada. Estas limitaciones y la falta de diversidad facilitan el modelado de cómo las acciones afectan a los píxeles, pero los mundos de juego imponen un límite bajo y conocido a lo que es posible con estos modelos.
Creemos que aprender tanto los píxeles como las acciones a partir de décadas de videos de la vida real (como lo que ves a continuación) tiene el potencial de levantar ese techo, desbloqueando modelos que aprenden imágenes realistas y la gama completa e ilimitada de acciones que realizamos en el mundo, más allá de la lógica del juego tradicional de caminar aquí, correr allá, disparar eso.
Aprendiendo el mundo realAprender de videos reales de final abierto es un problema increíblemente difícil. Las imágenes son ruidosas y diversas, las acciones son continuas e impredecibles, y la física es, en definitiva, real. Pero es lo que, en última instancia, permitirá que los modelos generen un realismo sin precedentes.
Un modelo mundial, no un modelo de vídeo.A primera vista, el vídeo interactivo parece una aplicación ideal de los modelos de vídeo. Sin embargo, la arquitectura, el número de parámetros y los conjuntos de datos de los modelos de vídeo típicos no son propicios para generar vídeo en tiempo real influenciado por las acciones del usuario.
Modelo mundialPredice un cuadro a la vez, reaccionando a lo que sucede.
Todo futuro es posible.
Totalmente interactivo: responde instantáneamente a la entrada del usuario en cualquier momento.
Modelo de vídeoGenera un vídeo completo de una sola vez.
El modelo conoce el final desde el principio.
No hay interactividad: el clip se reproduce igual cada vez.
Como ejemplo de diferencia, los modelos de vídeo generan un conjunto fijo de fotogramas de una sola vez. Para ello, crean una incrustación estructurada que representa un clip completo, lo cual funciona muy bien para la generación de clips, donde no es necesario cambiar nada durante la transmisión, pero impide la interactividad. Una vez configurada la incrustación de vídeo, el usuario queda limitado, lo que significa que solo puede ajustar el vídeo a intervalos fijos.
Sin embargo, un modelo de mundo funciona de forma muy diferente. Predice el siguiente estado del mundo dado el estado actual y una acción, y puede hacerlo en un intervalo flexible. Dado que las nuevas entradas del usuario pueden ocurrir en cualquier momento, ese intervalo puede ser tan corto como un solo fotograma de vídeo, lo que permite al usuario guiar la generación de vídeo en tiempo real con sus acciones. Para el vídeo interactivo, esto es esencial.
Servido por infraestructura en tiempo realEl modelo de nuestra vista previa de investigación puede transmitir vídeo a hasta 30 FPS desde clústeres de GPU H100 en EE. UU. y la UE. En segundo plano, al pulsar una tecla, tocar una pantalla o mover un joystick, esa información se envía por cable al modelo. Con esa información y el historial de fotogramas, el modelo genera el siguiente fotograma que cree que debería ser y lo transmite en tiempo real.
Esta serie de pasos puede tardar tan solo 40 ms, lo que significa que las acciones que realiza se reflejan instantáneamente en el video que ve. El costo actual de la infraestructura que permite esta experiencia es de $1 a $2 por hora de usuario, dependiendo de la calidad del video que ofrecemos. Este costo está disminuyendo rápidamente, impulsado por la optimización de modelos, las inversiones en infraestructura y los impulsos de los modelos de lenguaje.
Ampliando la visión, creemos que será difícil ignorar las ramificaciones de cómo se “produce” el video interactivo, donde la IA puede imaginar experiencias interactivas únicas de manera instantánea a un costo relativo extremadamente bajo.
Está surgiendo una nueva forma de vídeoNuevas formas de contar historias siempre han surgido de las nuevas tecnologías: pintura, libros, fotografía, cine, radio, videojuegos, efectos visuales, redes sociales, streaming. Es una historia tan antigua como el tiempo.
El video interactivo, basado en modelos del mundo en tiempo real, es el futuro y abre la puerta a formas de entretenimiento completamente nuevas, donde se pueden generar y explorar historias a la carta, sin las limitaciones ni los costos de la producción tradicional. Creemos que, con el tiempo, todo lo que es video hoy en día (entretenimiento, publicidad, educación, capacitación, viajes y más) evolucionará hacia el video interactivo, todo impulsado por Odyssey.
El avance de la investigación que compartimos hoy es un humilde comienzo hacia este futuro increíblemente emocionante, ¡y estamos ansiosos por que lo pruebes y escuches lo que piensas!
Este avance de investigación fue posible gracias al increíble equipo de Odyssey.
Personal técnicoBen Graham, Boyu Liu, Gareth Cross, James Grieve, Jeff Hawke, Jon Sadeghi, Oliver Cameron, Philip Petrakian, Richard Shen, Robin Tweedie, Ryan Burgoyne, Sarah King, Sirish Srinivasan, Vinh-Dieu Lam, Zygmunt Łenyk.
Personal operativoAndy Kolkhorst, Jessica Inman.
Este no es un problema resueltoEste avance de investigación no es perfecto ni se trata de un problema de investigación resuelto. Si te interesan los desafíos en la frontera de la IA, estamos contratando activamente para diversos puestos —científicos investigadores, ingenieros de investigación, ingenieros de sistemas y rendimiento de aprendizaje automático, ingenieros de datos, etc.— en Silicon Valley, Londres y de forma remota.
Para que te hagas una idea de los tipos de desafíos que afrontarías, a continuación te presentamos algunos modos de fallo divertidos que hemos observado con nuestro modelo de mundo de próxima generación. Esperamos que disfrutes de estas extrañas y maravillosas generaciones tanto como nosotros.
https://odyssey.world/introducing-interactive-video 







![[oki]](/images/smilies/net_thumbsup.gif "Ok!")


.jpg?width=850&auto=webp&quality=95&format=jpg&disable=upscale)























![[carcajad]](/images/smilies/nuevos/risa_ani2.gif "carcajada")


 .
.